Evaluating Imputation Against Ground Truth Abundance Values
%load_ext autoreload
%autoreload 2
import numpy as np
import pandas as pd
from tqdm.auto import tqdm
import seaborn as sns
from pyproteonet.simulation import molecule_set_from_degree_distribution, simulate_protein_peptide_dataset, simulate_mcars, simulate_mnars_thresholding
from pyproteonet.aggregation import maxlfq
from pyproteonet.processing import logarithmize
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
Simulating a Dataset
# We define some degree distributions roughly assembling those of a real world dataset
protein_deg_distribution = [0, 0.1445, 0.1221, 0.1151, 0.0933, 0.0692, 0.0655, 0.0508, 0.0472, 0.0362, 0.0311, 0.0277, 0.0209, 0.0199, 0.0163, 0.0143,
0.012, 0.0105, 0.0093, 0.0087, 0.0081, 0.0063, 0.0063, 0.0055, 0.0054, 0.0043, 0.0043, 0.0042, 0.0039, 0.0037, 0.0034,
0.0031, 0.0022, 0.0021, 0.0019, 0.0019, 0.0019, 0.0015, 0.0012, 0.001, 0.001]
peptide_deg_distribution = [0, 0.9591, 0.0341, 0.0046, 0.0014]
First, we create a set of proteins with related peptides. Next, we simulate abundance values for those peptides
# We create a simulated dataset with 100 proteins and 10 samples
num_proteins = 100
num_samples = 10
# We use a simple heuristic to determine the number of peptides for the given number of proteins while still closely matching the degree distributions
protein_degs = np.round(num_proteins * np.array(protein_deg_distribution))
prot_edges = np.sum(np.arange(len(protein_deg_distribution)) * protein_degs)
num_peptides = 1
pep_edges = 0
while pep_edges < prot_edges:
num_peptides += 1
peptide_degs = np.round(num_peptides * np.array(peptide_deg_distribution))
pep_edges = np.sum(np.arange(len(peptide_deg_distribution)) * peptide_degs)
if pep_edges > prot_edges:
diff = pep_edges - prot_edges
for i in range(len(peptide_degs)-1, -1, -1):
if peptide_degs[i] > 0 and i <= diff:
peptide_degs[i] -= 1
diff -= i
if diff == 0:
break
# Create a protein peptide molecule set for the given number of proteins/peptides and degree distribution
ms = molecule_set_from_degree_distribution(molecule1_name='protein', molecule2_name='peptide', mapping_name='peptide-protein',
molecule1_degree_distribution=protein_degs, molecule2_degree_distribution=peptide_degs)
# Lets simulate some abundance values for the given molecule set
ds = simulate_protein_peptide_dataset(molecule_set=ms, mapping='peptide-protein', samples=num_samples,
log_abundance_mu=15.9, log_abundance_sigma=1.8,
log_protein_error_sigma=0.3, peptide_noise_sigma= 115005.3,
flyability_alpha=0.7, flyability_beta=2.1, simulate_flyability=True)
Finally, we incorporate some missing values (MNARs and MCARs)
simulate_mnars_thresholding(dataset=ds, thresh_mu=115005.3 / 2, thresh_sigma=115005.3 / 4, molecule='peptide', column='abundance',
result_column='abundance_missing', mask_column='is_mnar', inplace=True)
simulate_mcars(dataset=ds, amount=0.3, molecule='peptide', column='abundance', result_column='abundance_missing', mask_column='is_mcar', inplace=True)
<pyproteonet.data.dataset.Dataset at 0x7f78feb7e6e0>
df = ds.values['peptide'].df
df.is_mnar.sum() / df.shape[0], df.is_mcar.sum() / df.shape[0]
(0.0, 0.2996688741721854)
In the end all abundance/aggregated values are logarithmized as it is commonly done in proteomics because logarithmized values are more normally distributed.
ds = logarithmize(data=ds, columns=['abundance', 'abundance_gt', 'abundance_missing'])
MaxLFQ aggregation
ds.values['protein']['aggregated'] = maxlfq(dataset=ds, molecule='protein', mapping='peptide-protein', partner_column='abundance_missing',
min_ratios=2, median_fallback=False, is_log=True)
Now the ‘aggregated’ value column holds the aggregated values and the ‘abundance_gt’ value column which was written during the simulation holds the ground truth values
ds.values['protein'].df
| abundance_gt | aggregated | ||
|---|---|---|---|
| sample | id | ||
| sample0 | 0 | 15.681 | NaN |
| 1 | 16.349 | NaN | |
| 2 | 15.980 | NaN | |
| 3 | 15.953 | NaN | |
| 4 | 17.506 | NaN | |
| ... | ... | ... | ... |
| sample9 | 92 | 16.108 | 16.049 |
| 93 | 14.821 | 14.358 | |
| 94 | 16.364 | 16.816 | |
| 95 | 17.186 | 16.916 | |
| 96 | 17.538 | 17.259 |
970 rows × 2 columns
Missing Value Imputation
Pyproteonet provides a wide range of established imputation functions combining both native python implementation and wrappers around R packages for imputation functions where no Python implementation is available yet.
Here we use the high level api to impute on both protein and peptide level using a bunch of different imputation functions.
from pyproteonet.imputation import impute_molecule
imputation_methods = ["minprob", "mindet", "bpca", "missforest", "knn", "isvd", "dae"]
impute_molecule(dataset=ds, molecule='protein', column='aggregated', methods=imputation_methods)
impute_molecule(dataset=ds, molecule='peptide', column='abundance_missing', methods=imputation_methods)
Show code cell output
minprob minprob
[1] 0.2529305
mindet mindet
bpca bpca
missforest missforest
Iteration: 0
Iteration: 1
Iteration: 2
Iteration: 3
Iteration: 4
Iteration: 5
Iteration: 6
knn knn
isvd isvd
[IterativeSVD] Iter 1: observed MAE=0.942344
[IterativeSVD] Iter 2: observed MAE=0.350876
[IterativeSVD] Iter 3: observed MAE=0.258267
[IterativeSVD] Iter 4: observed MAE=0.227213
[IterativeSVD] Iter 5: observed MAE=0.211764
[IterativeSVD] Iter 6: observed MAE=0.204686
[IterativeSVD] Iter 7: observed MAE=0.200392
[IterativeSVD] Iter 8: observed MAE=0.197704
[IterativeSVD] Iter 9: observed MAE=0.195750
[IterativeSVD] Iter 10: observed MAE=0.194525
[IterativeSVD] Iter 11: observed MAE=0.193618
15.146899784126177
dae dae
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 725.728516 | 91.013054 | 00:00 |
| 1 | 709.095764 | 91.077766 | 00:00 |
| 2 | 708.331848 | 90.922592 | 00:00 |
| 3 | 705.660583 | 90.476593 | 00:00 |
| 4 | 696.783264 | 90.100899 | 00:00 |
| 5 | 685.555237 | 89.355019 | 00:00 |
| 6 | 672.083923 | 88.618347 | 00:00 |
| 7 | 653.671997 | 87.444458 | 00:00 |
| 8 | 632.348083 | 85.870407 | 00:00 |
| 9 | 608.691650 | 84.063354 | 00:00 |
| 10 | 582.108459 | 82.260605 | 00:00 |
| 11 | 555.385254 | 79.811363 | 00:00 |
| 12 | 528.457642 | 77.238266 | 00:00 |
| 13 | 503.068329 | 74.764008 | 00:00 |
| 14 | 478.512085 | 71.810822 | 00:00 |
| 15 | 455.935547 | 69.176422 | 00:00 |
| 16 | 434.320984 | 66.161781 | 00:00 |
| 17 | 414.498169 | 62.710480 | 00:00 |
| 18 | 396.038483 | 58.973877 | 00:00 |
| 19 | 378.899445 | 55.197704 | 00:00 |
| 20 | 363.228455 | 51.754570 | 00:00 |
| 21 | 348.546173 | 47.994987 | 00:00 |
| 22 | 335.909119 | 44.215851 | 00:00 |
| 23 | 323.789581 | 41.902397 | 00:00 |
| 24 | 312.636841 | 38.087860 | 00:00 |
| 25 | 302.076935 | 35.011318 | 00:00 |
| 26 | 291.629364 | 31.977169 | 00:00 |
| 27 | 282.320282 | 29.299732 | 00:00 |
| 28 | 273.569611 | 27.784550 | 00:00 |
| 29 | 265.416718 | 25.950260 | 00:00 |
| 30 | 257.404907 | 24.255640 | 00:00 |
| 31 | 250.069244 | 23.220112 | 00:00 |
| 32 | 243.216873 | 22.005398 | 00:00 |
| 33 | 236.291687 | 20.901123 | 00:00 |
| 34 | 230.121155 | 19.042309 | 00:00 |
| 35 | 224.284653 | 18.446800 | 00:00 |
| 36 | 218.718582 | 18.114464 | 00:00 |
| 37 | 213.279007 | 17.501831 | 00:00 |
| 38 | 207.986801 | 17.174189 | 00:00 |
| 39 | 203.142578 | 16.500206 | 00:00 |
| 40 | 198.317932 | 16.405998 | 00:00 |
| 41 | 194.001770 | 15.670680 | 00:00 |
| 42 | 189.928879 | 15.808111 | 00:00 |
| 43 | 186.135056 | 15.554245 | 00:00 |
| 44 | 182.421234 | 15.500771 | 00:00 |
| 45 | 178.827637 | 15.241837 | 00:00 |
| 46 | 175.299973 | 14.754601 | 00:00 |
| 47 | 172.087616 | 14.403175 | 00:00 |
| 48 | 169.119553 | 14.403598 | 00:00 |
| 49 | 166.035294 | 14.120859 | 00:00 |
minprob minprob
[1] 0.2632525
mindet mindet
bpca bpca
missforest missforest
Iteration: 0
Iteration: 1
Iteration: 2
Iteration: 3
Iteration: 4
Iteration: 5
Iteration: 6
knn knn
isvd isvd
[IterativeSVD] Iter 1: observed MAE=3.272085
[IterativeSVD] Iter 2: observed MAE=0.941136
[IterativeSVD] Iter 3: observed MAE=0.464382
[IterativeSVD] Iter 4: observed MAE=0.322353
[IterativeSVD] Iter 5: observed MAE=0.266482
[IterativeSVD] Iter 6: observed MAE=0.237536
[IterativeSVD] Iter 7: observed MAE=0.219830
[IterativeSVD] Iter 8: observed MAE=0.208195
[IterativeSVD] Iter 9: observed MAE=0.200088
[IterativeSVD] Iter 10: observed MAE=0.194486
[IterativeSVD] Iter 11: observed MAE=0.190412
[IterativeSVD] Iter 12: observed MAE=0.187479
16.010288091787228
dae dae
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 4493.552246 | 404.716217 | 00:00 |
| 1 | 4468.966309 | 404.322144 | 00:00 |
| 2 | 4447.557129 | 403.467987 | 00:00 |
| 3 | 4409.976562 | 402.153320 | 00:00 |
| 4 | 4379.576172 | 400.218506 | 00:00 |
| 5 | 4323.508301 | 397.358063 | 00:00 |
| 6 | 4260.140137 | 393.432800 | 00:00 |
| 7 | 4182.843750 | 388.475464 | 00:00 |
| 8 | 4094.818604 | 382.642151 | 00:00 |
| 9 | 3987.919189 | 375.565155 | 00:00 |
| 10 | 3867.635254 | 367.591614 | 00:00 |
| 11 | 3742.343994 | 356.750305 | 00:00 |
| 12 | 3611.705078 | 345.030212 | 00:00 |
| 13 | 3477.803711 | 332.897705 | 00:00 |
| 14 | 3342.454590 | 322.812622 | 00:00 |
| 15 | 3210.765625 | 310.069885 | 00:00 |
| 16 | 3085.559082 | 295.018188 | 00:00 |
| 17 | 2965.295166 | 281.148682 | 00:00 |
| 18 | 2848.843262 | 268.510559 | 00:00 |
| 19 | 2739.402832 | 256.520935 | 00:00 |
| 20 | 2636.009521 | 242.482666 | 00:00 |
| 21 | 2540.154541 | 231.278122 | 00:00 |
| 22 | 2447.782715 | 221.356979 | 00:00 |
| 23 | 2359.931641 | 213.276093 | 00:00 |
| 24 | 2279.674805 | 206.133545 | 00:00 |
| 25 | 2203.294678 | 198.306946 | 00:00 |
| 26 | 2131.332764 | 186.534164 | 00:00 |
| 27 | 2063.686279 | 176.166138 | 00:00 |
| 28 | 2000.210815 | 166.791840 | 00:00 |
| 29 | 1941.170044 | 158.309631 | 00:00 |
| 30 | 1883.979248 | 150.332123 | 00:00 |
| 31 | 1828.688477 | 141.152344 | 00:00 |
| 32 | 1778.762817 | 134.889053 | 00:00 |
| 33 | 1729.396118 | 129.041748 | 00:00 |
| 34 | 1682.929199 | 122.430740 | 00:00 |
| 35 | 1638.676758 | 117.555725 | 00:00 |
| 36 | 1597.069458 | 110.338028 | 00:00 |
| 37 | 1556.690430 | 105.001938 | 00:00 |
| 38 | 1518.916138 | 99.025734 | 00:00 |
| 39 | 1483.880737 | 92.003006 | 00:00 |
| 40 | 1449.457275 | 87.371155 | 00:00 |
| 41 | 1416.749023 | 82.971382 | 00:00 |
| 42 | 1386.405884 | 77.076126 | 00:00 |
| 43 | 1356.068481 | 72.550751 | 00:00 |
| 44 | 1328.091431 | 67.971817 | 00:00 |
| 45 | 1300.896484 | 66.230911 | 00:00 |
| 46 | 1274.791992 | 64.563316 | 00:00 |
| 47 | 1249.918091 | 62.941284 | 00:00 |
| 48 | 1226.718384 | 60.634460 | 00:00 |
| 49 | 1203.742554 | 57.658623 | 00:00 |
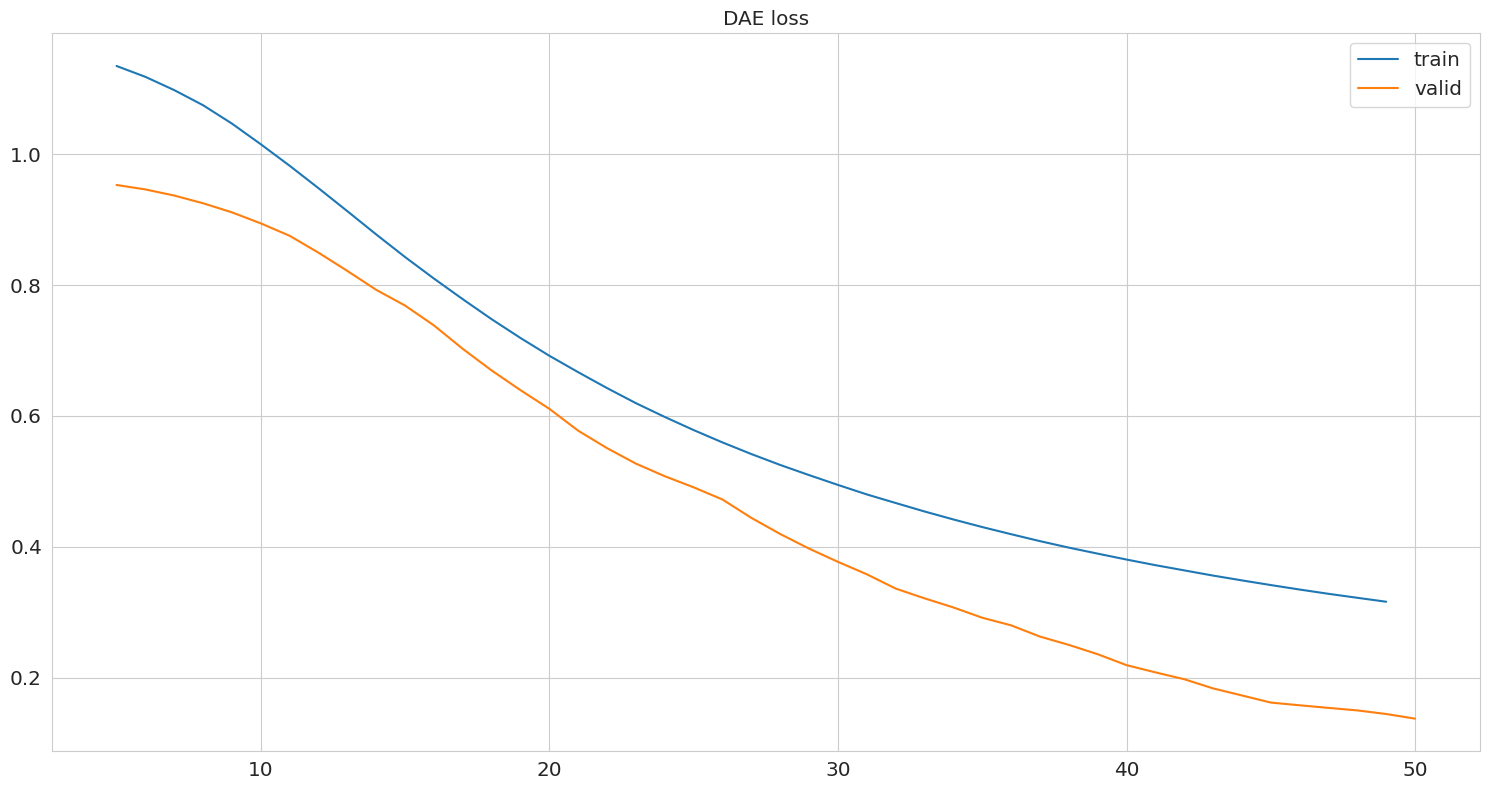
Looking at the result we can see that the missing values are gone:
ds.values['peptide'].df
| abundance | abundance_gt | abundance_missing | is_mnar | is_mcar | minprob | mindet | bpca | missforest | knn | isvd | dae | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sample | id | ||||||||||||
| sample0 | 0 | 15.295 | 15.681 | 15.295 | False | False | 15.295 | 15.295 | 15.295 | 15.295 | 15.295 | 15.295 | 15.295 |
| 1 | 16.469 | 16.349 | NaN | False | True | 12.429 | 12.393 | 16.614 | 16.566 | 16.625 | 16.446 | 16.406 | |
| 2 | 15.682 | 15.980 | NaN | False | True | 12.489 | 12.393 | 15.963 | 15.642 | 16.131 | 16.075 | 15.713 | |
| 3 | 16.372 | 15.953 | 16.372 | False | False | 16.372 | 16.372 | 16.372 | 16.372 | 16.372 | 16.372 | 16.372 | |
| 4 | 17.208 | 17.506 | 17.208 | False | False | 17.208 | 17.208 | 17.208 | 17.208 | 17.208 | 17.208 | 17.208 | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| sample9 | 599 | 17.746 | 17.807 | 17.746 | False | False | 17.746 | 17.746 | 17.746 | 17.746 | 17.746 | 17.746 | 17.746 |
| 600 | 18.388 | 18.548 | 18.388 | False | False | 18.388 | 18.388 | 18.388 | 18.388 | 18.388 | 18.388 | 18.388 | |
| 601 | 17.853 | 18.019 | NaN | False | True | 12.511 | 12.748 | 17.967 | 17.732 | 17.748 | 17.984 | 17.382 | |
| 602 | 18.369 | 18.595 | 18.369 | False | False | 18.369 | 18.369 | 18.369 | 18.369 | 18.369 | 18.369 | 18.369 | |
| 603 | 18.173 | 18.284 | 18.173 | False | False | 18.173 | 18.173 | 18.173 | 18.173 | 18.173 | 18.173 | 18.173 |
6040 rows × 12 columns
Graph Neural Network Imputation
from pyproteonet.imputation.dnn.gnn import impute_heterogeneous_gnn
_ = impute_heterogeneous_gnn(dataset=ds, molecule='protein', column='aggregated', mapping='peptide-protein', partner_column='abundance_missing',
molecule_result_column=f'gnn_hetero', partner_result_column=f'gnn_hetero',
max_epochs=1000, early_stopping_patience=7, epoch_size=30, training_fraction=0.25, log_every_n_steps=30)
Show code cell output
seed: 351895759
GPU available: True (cuda), used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
------------------------------------------------------
0 | embedding | Embedding | 485
1 | molecule_fc_model | Sequential | 11.0 K
2 | partner_fc_model | Sequential | 11.4 K
3 | molecule_gat | HeteroGraphConv | 34.4 K
4 | partner_gat | HeteroGraphConv | 50.4 K
5 | molecule_gat2 | HeteroGraphConv | 66.4 K
6 | molecule_linear | Linear | 820
7 | partner_linear | Linear | 1.2 K
8 | loss_fn | GaussianNLLLoss | 0
------------------------------------------------------
176 K Trainable params
0 Non-trainable params
176 K Total params
0.705 Total estimated model params size (MB)
step29: num_masked_molecule:706.0 || num_masked_partner:1026.800048828125 || molecule_loss:0.5021055936813354 || partner_loss:0.4748190641403198 || train_loss:0.9769246578216553 || epoch:0 ||
step59: num_masked_molecule:706.0 || num_masked_partner:1160.433349609375 || molecule_loss:0.3709450662136078 || partner_loss:0.12557192146778107 || train_loss:0.49651697278022766 || epoch:1 ||
step89: num_masked_molecule:706.0 || num_masked_partner:1090.5333251953125 || molecule_loss:-0.012235956266522408 || partner_loss:-0.33215370774269104 || train_loss:-0.34438958764076233 || epoch:2 ||
step119: num_masked_molecule:706.0 || num_masked_partner:1158.4666748046875 || molecule_loss:-0.32520750164985657 || partner_loss:-0.4651690125465393 || train_loss:-0.790376603603363 || epoch:3 ||
step149: num_masked_molecule:706.0 || num_masked_partner:1099.7332763671875 || molecule_loss:-0.4504413902759552 || partner_loss:-0.510000467300415 || train_loss:-0.9604418873786926 || epoch:4 ||
step179: num_masked_molecule:706.0 || num_masked_partner:1078.0 || molecule_loss:-0.5105648040771484 || partner_loss:-0.5449689030647278 || train_loss:-1.055533766746521 || epoch:5 ||
step209: num_masked_molecule:706.0 || num_masked_partner:990.6666870117188 || molecule_loss:-0.6079190373420715 || partner_loss:-0.61372971534729 || train_loss:-1.2216488122940063 || epoch:6 ||
step239: num_masked_molecule:706.0 || num_masked_partner:968.5999755859375 || molecule_loss:-0.6419838666915894 || partner_loss:-0.6361216306686401 || train_loss:-1.2781054973602295 || epoch:7 ||
step269: num_masked_molecule:706.0 || num_masked_partner:1091.7332763671875 || molecule_loss:-0.6184263825416565 || partner_loss:-0.6072388887405396 || train_loss:-1.2256652116775513 || epoch:8 ||
step299: num_masked_molecule:706.0 || num_masked_partner:994.2000122070312 || molecule_loss:-0.7532567381858826 || partner_loss:-0.7296491861343384 || train_loss:-1.4829059839248657 || epoch:9 ||
step329: num_masked_molecule:706.0 || num_masked_partner:1048.4000244140625 || molecule_loss:-0.7736703753471375 || partner_loss:-0.7557526230812073 || train_loss:-1.5294231176376343 || epoch:10 ||
step359: num_masked_molecule:706.0 || num_masked_partner:1050.4666748046875 || molecule_loss:-0.7907215356826782 || partner_loss:-0.7705901861190796 || train_loss:-1.5613116025924683 || epoch:11 ||
step389: num_masked_molecule:706.0 || num_masked_partner:1090.3333740234375 || molecule_loss:-0.7522632479667664 || partner_loss:-0.767548143863678 || train_loss:-1.5198115110397339 || epoch:12 ||
step419: num_masked_molecule:706.0 || num_masked_partner:1026.86669921875 || molecule_loss:-0.806643545627594 || partner_loss:-0.7848774790763855 || train_loss:-1.5915215015411377 || epoch:13 ||
step449: num_masked_molecule:706.0 || num_masked_partner:1015.0333251953125 || molecule_loss:-0.8478059768676758 || partner_loss:-0.8209801316261292 || train_loss:-1.668785810470581 || epoch:14 ||
step479: num_masked_molecule:706.0 || num_masked_partner:1064.300048828125 || molecule_loss:-0.8574027419090271 || partner_loss:-0.8280267715454102 || train_loss:-1.6854294538497925 || epoch:15 ||
step509: num_masked_molecule:706.0 || num_masked_partner:958.933349609375 || molecule_loss:-0.8429433107376099 || partner_loss:-0.8150697350502014 || train_loss:-1.658013105392456 || epoch:16 ||
step539: num_masked_molecule:706.0 || num_masked_partner:1020.7333374023438 || molecule_loss:-0.8313974738121033 || partner_loss:-0.81135493516922 || train_loss:-1.6427521705627441 || epoch:17 ||
step569: num_masked_molecule:706.0 || num_masked_partner:1027.933349609375 || molecule_loss:-0.8664554357528687 || partner_loss:-0.8272954225540161 || train_loss:-1.6937506198883057 || epoch:18 ||
step599: num_masked_molecule:706.0 || num_masked_partner:1179.800048828125 || molecule_loss:-0.8586979508399963 || partner_loss:-0.8399512767791748 || train_loss:-1.6986489295959473 || epoch:19 ||
step629: num_masked_molecule:706.0 || num_masked_partner:1107.13330078125 || molecule_loss:-0.758622944355011 || partner_loss:-0.7492792010307312 || train_loss:-1.5079021453857422 || epoch:20 ||
step659: num_masked_molecule:706.0 || num_masked_partner:1056.9000244140625 || molecule_loss:-0.8923173546791077 || partner_loss:-0.8846205472946167 || train_loss:-1.7769378423690796 || epoch:21 ||
step689: num_masked_molecule:706.0 || num_masked_partner:1156.0999755859375 || molecule_loss:-0.8382619023323059 || partner_loss:-0.7892665863037109 || train_loss:-1.627528429031372 || epoch:22 ||
step719: num_masked_molecule:706.0 || num_masked_partner:998.1333618164062 || molecule_loss:-0.9267680644989014 || partner_loss:-0.9003163576126099 || train_loss:-1.8270844221115112 || epoch:23 ||
step749: num_masked_molecule:706.0 || num_masked_partner:1127.933349609375 || molecule_loss:-0.9382941722869873 || partner_loss:-0.9007239937782288 || train_loss:-1.8390179872512817 || epoch:24 ||
step779: num_masked_molecule:706.0 || num_masked_partner:1018.5999755859375 || molecule_loss:-0.9493134021759033 || partner_loss:-0.9253332614898682 || train_loss:-1.8746470212936401 || epoch:25 ||
step809: num_masked_molecule:706.0 || num_masked_partner:1107.6666259765625 || molecule_loss:-0.9543604254722595 || partner_loss:-0.9190396666526794 || train_loss:-1.873400330543518 || epoch:26 ||
step839: num_masked_molecule:706.0 || num_masked_partner:1085.300048828125 || molecule_loss:-0.933240532875061 || partner_loss:-0.895464301109314 || train_loss:-1.828704595565796 || epoch:27 ||
step869: num_masked_molecule:706.0 || num_masked_partner:1079.0999755859375 || molecule_loss:-0.9389467239379883 || partner_loss:-0.9173352718353271 || train_loss:-1.856282114982605 || epoch:28 ||
step899: num_masked_molecule:706.0 || num_masked_partner:1007.8666381835938 || molecule_loss:-0.9523510336875916 || partner_loss:-0.9178689122200012 || train_loss:-1.8702200651168823 || epoch:29 ||
step929: num_masked_molecule:706.0 || num_masked_partner:930.566650390625 || molecule_loss:-0.9857296347618103 || partner_loss:-0.9465729594230652 || train_loss:-1.932302713394165 || epoch:30 ||
step959: num_masked_molecule:706.0 || num_masked_partner:1076.4666748046875 || molecule_loss:-0.9728419184684753 || partner_loss:-0.9399837851524353 || train_loss:-1.9128258228302002 || epoch:31 ||
step989: num_masked_molecule:706.0 || num_masked_partner:1027.3333740234375 || molecule_loss:-1.0037721395492554 || partner_loss:-0.9678016304969788 || train_loss:-1.9715734720230103 || epoch:32 ||
step1019: num_masked_molecule:706.0 || num_masked_partner:1077.36669921875 || molecule_loss:-1.0080838203430176 || partner_loss:-0.9495093822479248 || train_loss:-1.957593321800232 || epoch:33 ||
step1049: num_masked_molecule:706.0 || num_masked_partner:1100.566650390625 || molecule_loss:-0.9795469641685486 || partner_loss:-0.9460999369621277 || train_loss:-1.9256469011306763 || epoch:34 ||
step1079: num_masked_molecule:706.0 || num_masked_partner:1154.0 || molecule_loss:-0.9345295429229736 || partner_loss:-0.9085943698883057 || train_loss:-1.843124270439148 || epoch:35 ||
step1109: num_masked_molecule:706.0 || num_masked_partner:950.7333374023438 || molecule_loss:-1.0188764333724976 || partner_loss:-0.9866272211074829 || train_loss:-2.0055034160614014 || epoch:36 ||
step1139: num_masked_molecule:706.0 || num_masked_partner:1053.4666748046875 || molecule_loss:-1.0177667140960693 || partner_loss:-0.9690415859222412 || train_loss:-1.9868087768554688 || epoch:37 ||
step1169: num_masked_molecule:706.0 || num_masked_partner:1112.13330078125 || molecule_loss:-1.0239351987838745 || partner_loss:-0.9681205749511719 || train_loss:-1.9920555353164673 || epoch:38 ||
step1199: num_masked_molecule:706.0 || num_masked_partner:1150.0333251953125 || molecule_loss:-1.036136269569397 || partner_loss:-0.987048327922821 || train_loss:-2.0231850147247314 || epoch:39 ||
step1229: num_masked_molecule:706.0 || num_masked_partner:982.2000122070312 || molecule_loss:-1.0431923866271973 || partner_loss:-1.0042524337768555 || train_loss:-2.0474445819854736 || epoch:40 ||
step1259: num_masked_molecule:706.0 || num_masked_partner:1129.4666748046875 || molecule_loss:-1.024781346321106 || partner_loss:-0.9864785671234131 || train_loss:-2.0112600326538086 || epoch:41 ||
step1289: num_masked_molecule:706.0 || num_masked_partner:1092.0999755859375 || molecule_loss:-1.0318939685821533 || partner_loss:-1.0066903829574585 || train_loss:-2.038583993911743 || epoch:42 ||
step1319: num_masked_molecule:706.0 || num_masked_partner:1045.199951171875 || molecule_loss:-1.0409079790115356 || partner_loss:-1.0015157461166382 || train_loss:-2.0424234867095947 || epoch:43 ||
step1349: num_masked_molecule:706.0 || num_masked_partner:1131.5 || molecule_loss:-1.0382781028747559 || partner_loss:-0.9959096312522888 || train_loss:-2.0341877937316895 || epoch:44 ||
step1379: num_masked_molecule:706.0 || num_masked_partner:983.7333374023438 || molecule_loss:-1.057854175567627 || partner_loss:-1.0095196962356567 || train_loss:-2.067373752593994 || epoch:45 ||
step1409: num_masked_molecule:706.0 || num_masked_partner:1011.4666748046875 || molecule_loss:-1.0266164541244507 || partner_loss:-0.9871013760566711 || train_loss:-2.0137178897857666 || epoch:46 ||
step1439: num_masked_molecule:706.0 || num_masked_partner:1082.2667236328125 || molecule_loss:-1.044403314590454 || partner_loss:-1.0015701055526733 || train_loss:-2.045973539352417 || epoch:47 ||
step1469: num_masked_molecule:706.0 || num_masked_partner:1065.7667236328125 || molecule_loss:-1.0337443351745605 || partner_loss:-0.9949927926063538 || train_loss:-2.0287368297576904 || epoch:48 ||
step1499: num_masked_molecule:706.0 || num_masked_partner:1039.9666748046875 || molecule_loss:-1.0541470050811768 || partner_loss:-0.9889230132102966 || train_loss:-2.0430703163146973 || epoch:49 ||
step1529: num_masked_molecule:706.0 || num_masked_partner:1022.5999755859375 || molecule_loss:-1.071032166481018 || partner_loss:-1.0220104455947876 || train_loss:-2.0930426120758057 || epoch:50 ||
step1559: num_masked_molecule:706.0 || num_masked_partner:1079.433349609375 || molecule_loss:-1.0609084367752075 || partner_loss:-1.0071407556533813 || train_loss:-2.068049192428589 || epoch:51 ||
step1589: num_masked_molecule:706.0 || num_masked_partner:997.5 || molecule_loss:-1.0327026844024658 || partner_loss:-1.0056102275848389 || train_loss:-2.038313150405884 || epoch:52 ||
step1619: num_masked_molecule:706.0 || num_masked_partner:1013.1333618164062 || molecule_loss:-1.0988285541534424 || partner_loss:-1.039958119392395 || train_loss:-2.1387863159179688 || epoch:53 ||
step1649: num_masked_molecule:706.0 || num_masked_partner:1085.6666259765625 || molecule_loss:-1.0658906698226929 || partner_loss:-1.0185890197753906 || train_loss:-2.084479570388794 || epoch:54 ||
step1679: num_masked_molecule:706.0 || num_masked_partner:923.7999877929688 || molecule_loss:-1.0951734781265259 || partner_loss:-1.0456804037094116 || train_loss:-2.1408538818359375 || epoch:55 ||
step1709: num_masked_molecule:706.0 || num_masked_partner:1113.7332763671875 || molecule_loss:-1.0575143098831177 || partner_loss:-1.0204428434371948 || train_loss:-2.0779569149017334 || epoch:56 ||
step1739: num_masked_molecule:706.0 || num_masked_partner:1064.7332763671875 || molecule_loss:-1.0925005674362183 || partner_loss:-1.0493261814117432 || train_loss:-2.141826629638672 || epoch:57 ||
step1769: num_masked_molecule:706.0 || num_masked_partner:1054.066650390625 || molecule_loss:-1.084751009941101 || partner_loss:-1.0421618223190308 || train_loss:-2.126912832260132 || epoch:58 ||
step1799: num_masked_molecule:706.0 || num_masked_partner:1163.5333251953125 || molecule_loss:-1.0990279912948608 || partner_loss:-1.0486626625061035 || train_loss:-2.147690534591675 || epoch:59 ||
step1829: num_masked_molecule:706.0 || num_masked_partner:1080.7332763671875 || molecule_loss:-1.1158238649368286 || partner_loss:-1.053543210029602 || train_loss:-2.1693673133850098 || epoch:60 ||
step1859: num_masked_molecule:706.0 || num_masked_partner:1100.8333740234375 || molecule_loss:-1.0958619117736816 || partner_loss:-1.0411535501480103 || train_loss:-2.1370155811309814 || epoch:61 ||
step1889: num_masked_molecule:706.0 || num_masked_partner:1056.066650390625 || molecule_loss:-1.1076759099960327 || partner_loss:-1.0397175550460815 || train_loss:-2.1473934650421143 || epoch:62 ||
step1919: num_masked_molecule:706.0 || num_masked_partner:1096.433349609375 || molecule_loss:-1.1148617267608643 || partner_loss:-1.0689504146575928 || train_loss:-2.183812379837036 || epoch:63 ||
step1949: num_masked_molecule:706.0 || num_masked_partner:1039.199951171875 || molecule_loss:-1.1124831438064575 || partner_loss:-1.064082384109497 || train_loss:-2.176565408706665 || epoch:64 ||
step1979: num_masked_molecule:706.0 || num_masked_partner:1049.566650390625 || molecule_loss:-1.1219178438186646 || partner_loss:-1.0634821653366089 || train_loss:-2.1854004859924316 || epoch:65 ||
step2009: num_masked_molecule:706.0 || num_masked_partner:1072.9000244140625 || molecule_loss:-1.1082804203033447 || partner_loss:-1.052480936050415 || train_loss:-2.1607613563537598 || epoch:66 ||
step2039: num_masked_molecule:706.0 || num_masked_partner:1000.2333374023438 || molecule_loss:-1.1242812871932983 || partner_loss:-1.0726218223571777 || train_loss:-2.1969032287597656 || epoch:67 ||
step2069: num_masked_molecule:706.0 || num_masked_partner:1071.9000244140625 || molecule_loss:-1.1164376735687256 || partner_loss:-1.0617098808288574 || train_loss:-2.178147315979004 || epoch:68 ||
step2099: num_masked_molecule:706.0 || num_masked_partner:1065.433349609375 || molecule_loss:-1.1219402551651 || partner_loss:-1.0614031553268433 || train_loss:-2.1833431720733643 || epoch:69 ||
step2129: num_masked_molecule:706.0 || num_masked_partner:933.8333129882812 || molecule_loss:-1.1334900856018066 || partner_loss:-1.0872844457626343 || train_loss:-2.2207746505737305 || epoch:70 ||
step2159: num_masked_molecule:706.0 || num_masked_partner:1012.0999755859375 || molecule_loss:-1.139643907546997 || partner_loss:-1.09285569190979 || train_loss:-2.232499599456787 || epoch:71 ||
step2189: num_masked_molecule:706.0 || num_masked_partner:1070.4000244140625 || molecule_loss:-1.1274845600128174 || partner_loss:-1.0885952711105347 || train_loss:-2.2160797119140625 || epoch:72 ||
step2219: num_masked_molecule:706.0 || num_masked_partner:997.0 || molecule_loss:-1.1332112550735474 || partner_loss:-1.0625876188278198 || train_loss:-2.195798635482788 || epoch:73 ||
step2249: num_masked_molecule:706.0 || num_masked_partner:1010.433349609375 || molecule_loss:-1.1446971893310547 || partner_loss:-1.0848357677459717 || train_loss:-2.2295329570770264 || epoch:74 ||
step2279: num_masked_molecule:706.0 || num_masked_partner:1121.63330078125 || molecule_loss:-1.1328314542770386 || partner_loss:-1.076156735420227 || train_loss:-2.2089881896972656 || epoch:75 ||
step2309: num_masked_molecule:706.0 || num_masked_partner:1091.5999755859375 || molecule_loss:-1.152953863143921 || partner_loss:-1.0956823825836182 || train_loss:-2.24863600730896 || epoch:76 ||
step2339: num_masked_molecule:706.0 || num_masked_partner:1058.36669921875 || molecule_loss:-1.15134596824646 || partner_loss:-1.0903767347335815 || train_loss:-2.241722583770752 || epoch:77 ||
step2369: num_masked_molecule:706.0 || num_masked_partner:993.8333129882812 || molecule_loss:-1.1373097896575928 || partner_loss:-1.0991852283477783 || train_loss:-2.23649525642395 || epoch:78 ||
step2399: num_masked_molecule:706.0 || num_masked_partner:1059.6666259765625 || molecule_loss:-1.1557230949401855 || partner_loss:-1.101866602897644 || train_loss:-2.25758957862854 || epoch:79 ||
step2429: num_masked_molecule:706.0 || num_masked_partner:1103.4666748046875 || molecule_loss:-1.1524230241775513 || partner_loss:-1.0957988500595093 || train_loss:-2.2482216358184814 || epoch:80 ||
step2459: num_masked_molecule:706.0 || num_masked_partner:1028.566650390625 || molecule_loss:-1.16344153881073 || partner_loss:-1.1027735471725464 || train_loss:-2.2662158012390137 || epoch:81 ||
step2489: num_masked_molecule:706.0 || num_masked_partner:976.2999877929688 || molecule_loss:-1.1658706665039062 || partner_loss:-1.1084386110305786 || train_loss:-2.2743096351623535 || epoch:82 ||
step2519: num_masked_molecule:706.0 || num_masked_partner:1003.7333374023438 || molecule_loss:-1.1428661346435547 || partner_loss:-1.0996185541152954 || train_loss:-2.2424845695495605 || epoch:83 ||
step2549: num_masked_molecule:706.0 || num_masked_partner:1014.3333129882812 || molecule_loss:-1.1486085653305054 || partner_loss:-1.1001842021942139 || train_loss:-2.248792886734009 || epoch:84 ||
step2579: num_masked_molecule:706.0 || num_masked_partner:958.5 || molecule_loss:-1.1815340518951416 || partner_loss:-1.1107405424118042 || train_loss:-2.2922744750976562 || epoch:85 ||
step2609: num_masked_molecule:706.0 || num_masked_partner:1176.5999755859375 || molecule_loss:-1.1537457704544067 || partner_loss:-1.0964839458465576 || train_loss:-2.250230073928833 || epoch:86 ||
step2639: num_masked_molecule:706.0 || num_masked_partner:995.0999755859375 || molecule_loss:-1.157749056816101 || partner_loss:-1.097983717918396 || train_loss:-2.255732536315918 || epoch:87 ||
step2669: num_masked_molecule:706.0 || num_masked_partner:1127.9000244140625 || molecule_loss:-1.1710950136184692 || partner_loss:-1.105139136314392 || train_loss:-2.2762341499328613 || epoch:88 ||
step2699: num_masked_molecule:706.0 || num_masked_partner:1144.13330078125 || molecule_loss:-1.1701854467391968 || partner_loss:-1.1100586652755737 || train_loss:-2.2802443504333496 || epoch:89 ||
step2729: num_masked_molecule:706.0 || num_masked_partner:1079.2332763671875 || molecule_loss:-1.1851451396942139 || partner_loss:-1.1264252662658691 || train_loss:-2.311570405960083 || epoch:90 ||
step2759: num_masked_molecule:706.0 || num_masked_partner:1087.199951171875 || molecule_loss:-1.1831681728363037 || partner_loss:-1.1189769506454468 || train_loss:-2.30214524269104 || epoch:91 ||
step2789: num_masked_molecule:706.0 || num_masked_partner:1091.36669921875 || molecule_loss:-1.1657309532165527 || partner_loss:-1.1075778007507324 || train_loss:-2.273308515548706 || epoch:92 ||
step2819: num_masked_molecule:706.0 || num_masked_partner:1115.199951171875 || molecule_loss:-1.1752351522445679 || partner_loss:-1.1235820055007935 || train_loss:-2.2988173961639404 || epoch:93 ||
step2849: num_masked_molecule:706.0 || num_masked_partner:1043.5999755859375 || molecule_loss:-1.1790860891342163 || partner_loss:-1.11478853225708 || train_loss:-2.2938742637634277 || epoch:94 ||
step2879: num_masked_molecule:706.0 || num_masked_partner:1050.2667236328125 || molecule_loss:-1.1862127780914307 || partner_loss:-1.114065408706665 || train_loss:-2.300278425216675 || epoch:95 ||
step2909: num_masked_molecule:706.0 || num_masked_partner:980.2999877929688 || molecule_loss:-1.1831430196762085 || partner_loss:-1.118802785873413 || train_loss:-2.301945686340332 || epoch:96 ||
step2939: num_masked_molecule:706.0 || num_masked_partner:1032.7332763671875 || molecule_loss:-1.1847190856933594 || partner_loss:-1.1261345148086548 || train_loss:-2.3108534812927246 || epoch:97 ||
Just using pandas we can get the mean average error of the imputed values
df = ds.values['peptide'].df
for imp in imputation_methods + ['gnn_hetero']:
print(imp, (df[imp] - df['abundance_gt']).abs().mean())
minprob 1.161707908701399
mindet 1.1617361347381416
bpca 0.1944661251166557
missforest 0.2203599013751484
knn 0.2181944885286117
isvd 0.22642413639656336
dae 0.27632932655821524
gnn_hetero 0.1984486647359422
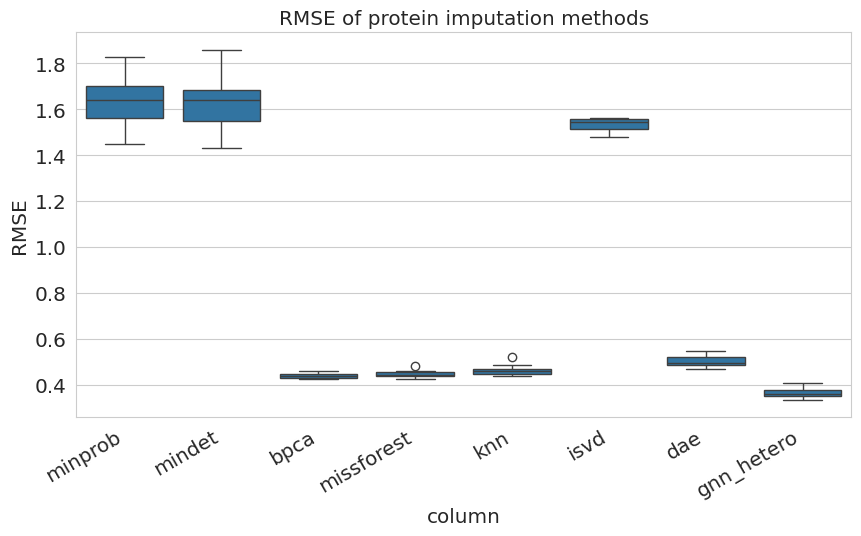
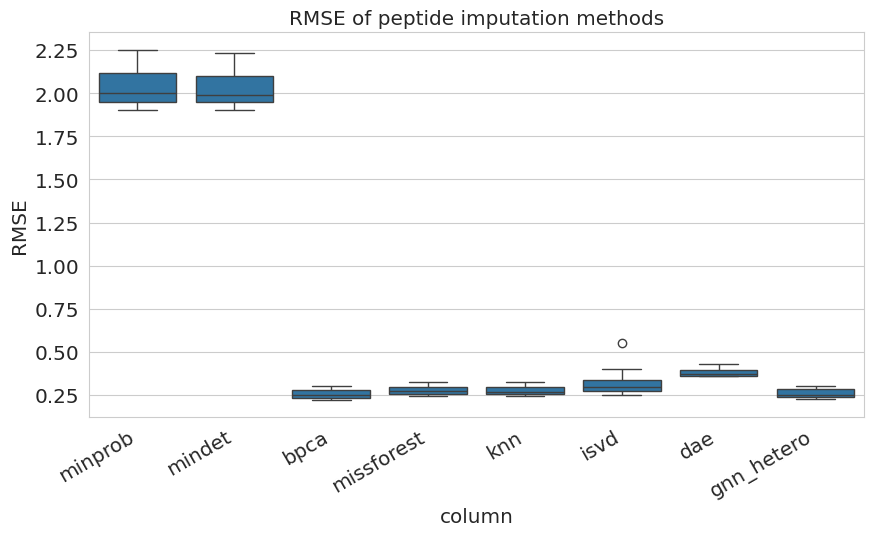
Evaluating every dataset sample individually gives a better idea of the variance of imputation results.
For this the compare_columns(...) can be used, returning the evaluation results according to an evaluation metrics. Here we use the RMSE.
Those can then be plotted using seaborn.
We evaluate both, protein and peptide imputation.
In addition, only evaluating molecules with a missingness <= 80% allows for a more fine grained evaluation.
from matplotlib import pyplot as plt
import seaborn as sns
from pyproteonet.metrics import compare_columns
for molecule in ['protein', 'peptide',]:
metric_df = compare_columns(
dataset=ds,
molecule=molecule,
columns=imputation_methods + ['gnn_hetero'],
comparison_column='abundance_gt',
metric='RMSE',
per_sample=True,
ignore_missing=False,
logarithmize=False,
replace_nan_metric_with=0,
)
metric_df.rename(columns={"metric": 'RMSE'}, inplace=True)
fig, ax = plt.subplots(figsize=(10, 5))
ax = sns.boxplot(
data=metric_df,
x="column",
y='RMSE',
ax=ax
)
_ = ax.set_xticklabels(ax.get_xticklabels(),rotation=30, ha='right')
ax.set_title(f'RMSE of {molecule} imputation methods')